简单记录一下自己在linux环境下使用scrapy爬取伯乐在线并提取结构性数据到数据库中的过程
项目环境
deepin15.7 + python 3.6 + mysql 5.5 + pycharm
搭建环境
- 安装python环境
- 安装pip
- 安装mysql
安装scrapy,virtualenv
- pip源推荐使用清华大学镜像源 https://pypi.tuna.tsinghua.edu.cn/simple
创建scrapy项目
在pycharm中创建一个虚拟环境,安装好环境后,在目录下面创建scrapy项目
1 | scrapy startproject ArticleSpider |
项目的结构如下
1 | ├── ArticleSpider |
分析网站中文章页面结构
先进入伯乐在线网站http://www.jobbole.com/,然后随便点开一篇文章
例如http://blog.jobbole.com/114297/
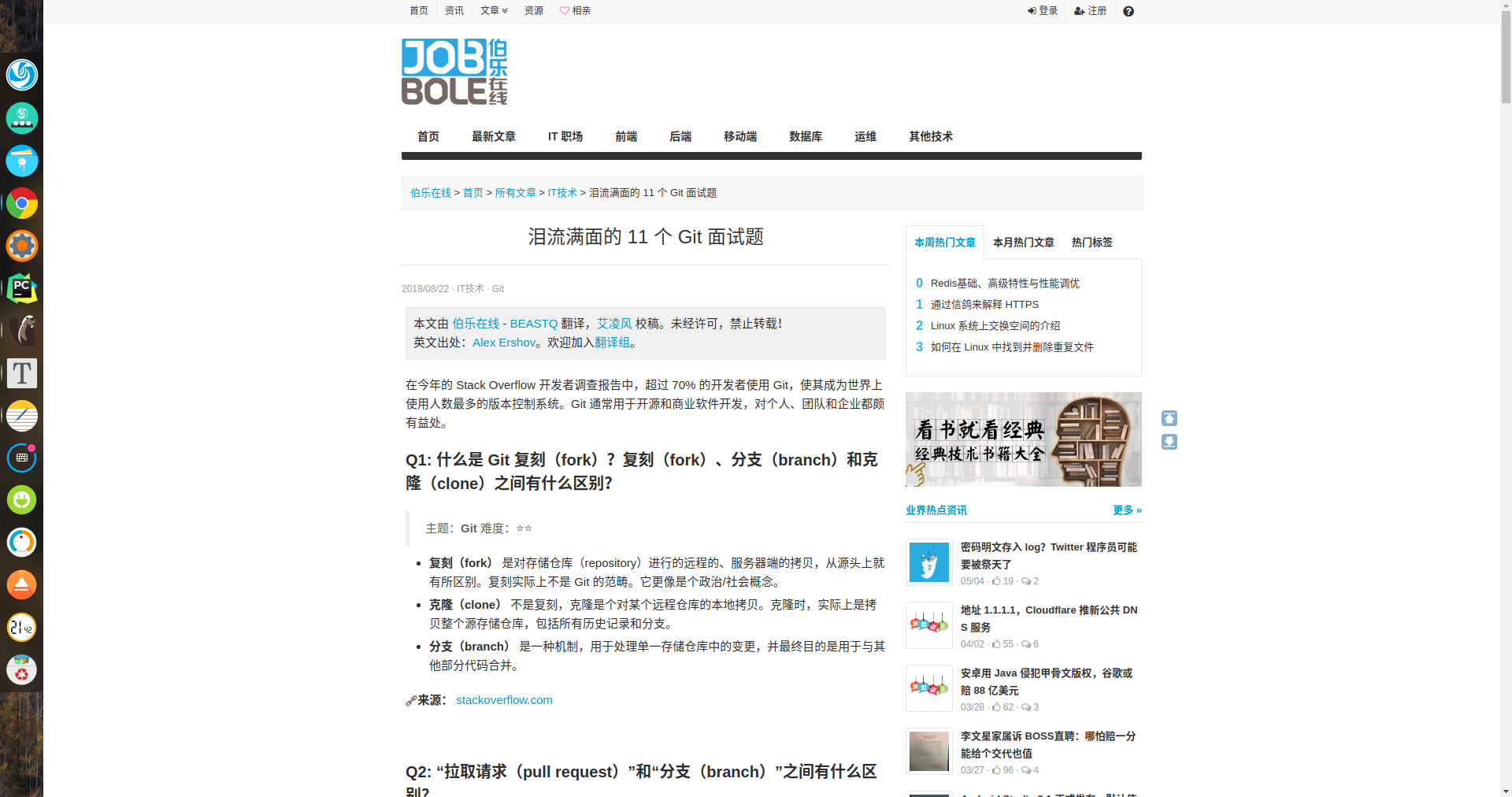
对于某一篇文章,目前只需要获得文章的评论数,收藏数,点赞数(默认为1),分类,标题,正文,文章封面图和文章链接。
在Chrome中按F12查看个元素的标签,例如文章的收藏数
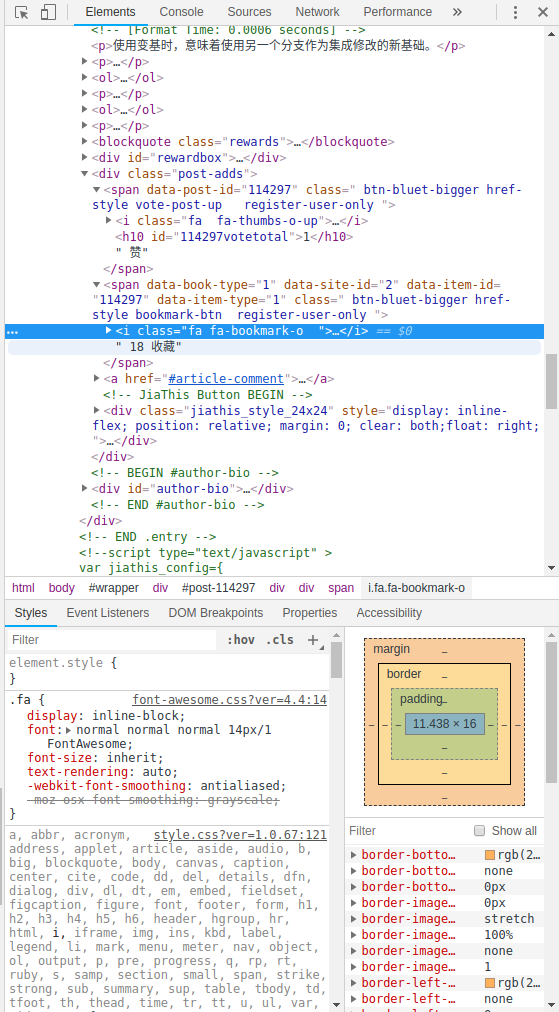
在scrapy shell中获取网页数据
scrapy提供了一个shell环境方便我们调试,并查看获取的元素是否正确
在venv目录的bin目录下
1 | source activate |
进入venv环境后输入
1 | scrapy shell http://blog.jobbole.com/114297/ |
进入到shell后用css选择器或xpath选择器选取刚才要获得的元素
1 | >> response.css('.bookmark-btn::text').extract() |
获得的是一个列表,因为class为bookmark-btn的元素只有一个,所以将上面的extract()改为extract_first(‘’)
1 | >> response.css('.bookmark-btn::text').extract_first() |
得到一个字符串,这时将其中的18用正则表达式提取出来后就可以获取到收藏数了,其他的也是如此
编写代码
从pycharm中启动项目
首先在项目根目录中打开命令行,创建爬虫文件
1 | scrapy genspider jobbole www.jobbole.com |
然后打开main文件
1 | from scrapy.cmdline import execute |
在main文件中只有两行执行的代码,
1 | sys.path.append(os.path.dirname(os.path.abspath(__file__))) |
是将当前的main文件所在目录,即根目录将入环境中,就可以调用别的py文件的方法和类
1 | execute(['scrapy', 'crawl', 'jobbole']) |
在第一行导入了scrapy.cmdline即scrapy命令行工具的execute方法,因为Scrapy是通过 scrapy 命令行工具进行控制的。 这里我们称之为 “Scrapy tool” 以用来和子命令进行区分。 对于子命令,我们称为 “command” 或者 “Scrapy commands”。上面代码即相当于执行了scrapy crawl jobbole
获取url
在jobbole.py中,其中的parse函数用来获取当前页中的所有文章url和下一页的url
1 | class JobboleSpider(scrapy.Spider): |
通过itemloader装载items
在scrapy中提供Item类,Item对象是种简单的容器,保存了爬取到得数据。 其提供了类似于词典(dictionary-like)的API以及用于声明可用字段的简单语法。
如果直接用Item类,如果后期要对代码进行维护就会变得很繁琐,使用ItemLoader类就可以自己编写函数来处理item中的数据,在jobbole.py中加入Item
1 | res_image_url = response.meta.get('front_image_url', '') |
Input and Output processors
Item Loader在每个(Item)字段中都包含了一个输入处理器和一个输出处理器。 输入处理器收到数据时立刻提取数据 (通过 add_xpath(), add_css() 或者 add_value() 方法) 之后输入处理器的结果被收集起来并且保存在ItemLoader内. 收集到所有的数据后, 调用 ItemLoader.load_item() 方法来填充,并得到填充后的 Item 对象. 这是当输出处理器被和之前收集到的数据(和用输入处理器处理的)被调用.输出处理器的结果是被分配到Item的最终值。
之后在Item.py中加入
1 | class JobBoleArticleItem(scrapy.Item): |
然后在settings.py中,将robots.txt规则设置为False
1 | ROBOTSTXT_OBEY = False |
这时爬虫项目大致完成,接下来配置数据库和pipelines
写入数据库
首先需要安装python的mysql-dev,在这里记录一下我遇到的坑,在linux下直接pip install mysql-python会出现错误,这时需要在外面打开命令行,执行sudo apt-get install libmysqlclient-dev后就可以安装了。
写入数据库有同步和异步的方法,这里只记录异步方法,因为同步方法出错让我卡了两个小时,爷吐了
1 | class MysqlTwistedPipline(object): |
在pipelines.py中如上配置,然后在settings.py的最后面加上数据库帐号密码之类的信息,再在items.py中编写get_insert_sql函数就可以将数据写入到数据库中了,而且不同的爬虫项目还可以复用这个结构,只需要改写get_insert_sql中的sql语句就可以了。
将图片和爬取的数据导出为Json文件
懒得写了,放在github上。